분야 : Multi-task Learning, Depth Estimation, Scene Parsing(Semantic Segmentation)
저자 : Dan Xu, Wanli Ouyang, Xiaogang Wang, Nicu Sebe
학회 : CVPR 2018
인용 수 : 486(2024.04.23 기준)
Introduction
이 논문은 Depth Estimation 과 Scene Parsing(이라고 설명하지만 Semantic Segmentation이다)을 동시에 수행하는 multi-task learning의 성능을 높이기 위해 새로운 네트워크(PAD-Net)를 제안한다. 또한 여기서 multi-modal distillation module 세 개를 만들었다고 한다.
PAD-Net

모델 구조는 위 사진과 같다. 과정 순서대로 설명을 해보자면 RGB Image → Front-End Encoder → Multi-Task Predictions → Multi-Modal Distillation → Decoder → Output Images(2개의 이미지) 순이다.
L1부터 L6은 Loss Funcition을 의미하고, DECONV는 Deconvolutional Operation을 의미한다.
Front-End Encoder

- CNN Encoder
입력이미지는 Encoder를 통해서 feature를 출력한다. 여기서 AlexNet, VGG, ResNet같은 아무 CNN모델을 Encoder로 사용해도 된다고 언급한다. 그래서 논문에서는 indoor data인 NYU depth V2(NYUD-v2)데이터에서는 AlexNet, outdoor data인 Cityscapes에서는 ResNet50을 사용했다고 한다.
- Aggregation and Concatenate
여기서는 CNN모델로 출력된 feature map만 사용하지 않는다. 출력 feature map을 강화하기 위해 각 layer의 출력들에 convolution과 bilinear interpolation을 사용하여 다운샘플링된 feature를 feature map 에 concat한다.
Multi-Task Predictions

Encoder로 생성된 feature maps은 다시 deconvolution되어서 4개의 각각의 task에 대해서 task-specific feature maps을 생성한다. 여기서 4개의 task-specific feature maps 들의 해상도는 입력으로 들어간 feature maps의 2배이다. 그리고 input으로 들어간 RGB이미지의 1/4크기이다.
그리고 주요 task만 N개의 채널을, 나머지는 N/2개의 채널을 가져온다고 하는데 해당 논문에서는 N=512이다.
Multi-Modal Distillation

논문에서 제안하는 세 가지의 Multi-Modal Distillation Modul은 위의 그림과 같다.
Y는 이전의 Prediction 과정에서 나온 feature maps이고, F는 이 feature maps에서 convolution layers를 거친 값이다. 둘의 차이점이라고 하면 F의 채널 수가 Y보다 더 많은거? i는 sample을 의미한다.
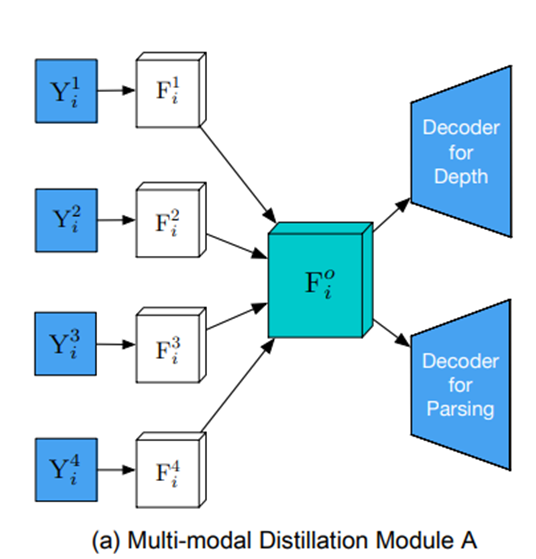
(a) Module A
$ t$ : tasks, $ t \in \{1,2,3,4\}$
$ k$ : final task, $ k \in \{1,4\}$
$CONCAT$ : concatenation
$i$ : training samples
Module A는 $F_i^o \leftarrow CONCAT(F_i^1, ..., F_i^T)$이다.
(b) Module B
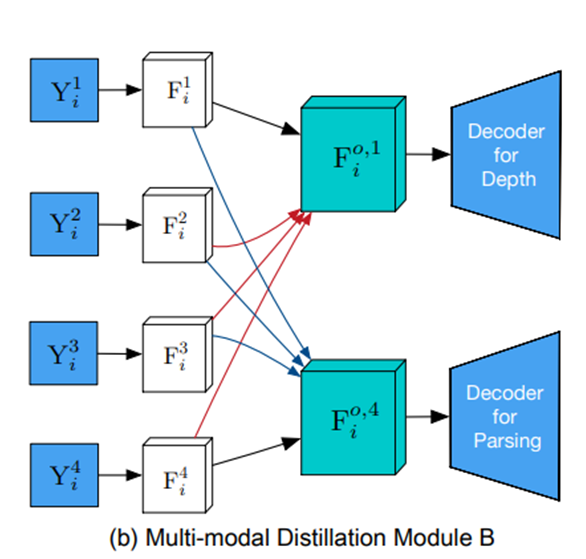
B는 message passing 방법을 사용한 모듈이라고 한다.
$F_i^{o, k} $ : feature map after distillation
$F_i^k $ : feature map before massage passing
$i$ : training sample
$W_{t,k}$ : convolution kernel t-th feature map and k-th feature map
Module B는 아래와 같다.
$F_i^{o,k} \leftarrow F_i^k + \sum_{t=1(\neq k)}^T (W_{t,k} \otimes F_i^t)$
만약에 $k=1$을 대입해 보면 아래와 같다.

$F_i^{1}$ 에 나머지 F들은 각각의 가중치를 곱하여 더해지는 값과 같다고 할 수 있다.
(c) Module C

C는 attention-guided message passing이다.
$W_g^k$ : convolution parameter
$\sigma$ : sigmoid
$\odot$ : element-wise multiplication
$G_i^k$ : attention map

여기서 sigmoid는 normalize를 위해서 사용했다고 한다. 그리고 이 $G_i^k$를 최종 message는 다음 연산으로 완성된다.
$F_i^{o,k} \leftarrow F_i^k + \sum^T_{t=1(\neq k)} G_i^k \odot (W_t \otimes F_i^t)$
만약 $k = 1$을 대입해 보면 아래와 같다.
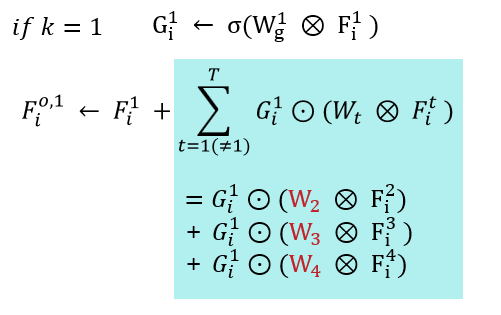
Decoder
2개의 layer로 구성되었고, 하나의 layer당 해상도는 2배가 되고, 채널 수는 2배로 나뉜다.
Loss
