Chapter 02-2는 "웹 스크래핑"에 대해 알아본다.
도서 쪽수를 찾아서
- 웹 스크래핑(또는 웹 크롤링) : 프로그램으로 웹사이트이 페이지를 옮겨 가면서 데이터를 추출하는 작업
- 사이트에서 직접 데이터를 찾는 것은 API로 url에 파라미터를 붙여서 찾는 것과는 조금 다름.
- Yes24 사이트에서 는 도서 제목이나 ISBN으로 검색을 해서 도서 상세 페이지로 넘어감.
검색 결과 페이지 가져오기
import gdown
gdown.download('https://bit.ly/3q9SZix', '20s_best_book.json',quiet=False)import pandas as pd
books_df = pd.read_json('20s_best_book.json')
books_df.head()# 열이 많아 no 부터 isbn13열까지만 가져오기
books = books_df[['no','ranking','bookname','authors','publisher','publication_year','isbn13']]
books.head()데이터 프레임 행과 열 선택하기:loc 메서드검색 결과 페이지 HTML 가져오기: requests.get() 함수
- requests 패키지 임포트 후 request.get()함수로 도서 정보 가져오기
- 1. 도서의 ISBN과 Yes24 검색 결과 페이지 URL을 위한 변수 정의
- 2. requests.get() 함수 호출 시 파이썬 문자열의 format() 메서드를 사용-isbn변수에 저장된 값을 url변수에 전달
검색 결과 페이지 HTML 가져오기: requests.get() 함수
import requests
isbn = 9791190090018 # '우리가 빛의 속도로 갈 수 없다면'의 ISBN
url = 'http://www.yes24.com/Product/Search?domain=BOOK&query={}'
r = requests.get(url.format(isbn))
# requests.get함수가 반환한 응답 객체
print(r.text)HTML에서 데이터 추출하기: 뷰티플수프
HTML 안에 있는 내용을 찾을 때는 뷰티플수프를 사용한다.
크롬 개발자 도구로 HTML 태그 찾기
- Yes24웹 사이트에서 첫 번째 도서의 ISBN인 9791190090018 검색-마우스 오른쪽 팝업-[검사]
- 개발자 도구(또는 F12)
- Select 부분 클릭하면 마우스로 태그찾기 쉽다

from bs4 import BeautifulSoup
# 객체 생성: 첫 번째는 파싱할 HTML문서, 두 번째는 파싱에 사용할 파서
soup = BeautifulSoup(r.text, 'html.parser')태그 위치 찾기:find() 메서드
첫 번재 매개변수에는 찾을 태그 이름을 지정, attrs 매개변수에는 찾으려는 태그 속성을 딕셔너리로 지정
# prd_link는 뷰티플수프의 Tag 클래스 객체
prd_link = soup.find('a',attrs ={'class':'gd_name'})
print(prd_link)
# 태그 안 속성 참조
print(prd_link['href'])도서 상세 페이지 HTML 가져오기

# '우리가 빛의 속도로 갈 수 없다면'의 상세 페이지 가져오기
url = 'http://www.yes24.com'+prd_link['href']
r = requests.get(url)
print(r.text)
soup = BeautifulSoup(r.text, 'html.parser')
prd_detail = soup.find('div',attrs = {'id':'infoset_specific'})
print(prd_detail)테이블 태그를 리스트로 가져오기:find_all() 메서드
'쪽수, 무게, 크기' 부분은 <tr> 태그의 <td> 태그에서 볼 수 있다.
prd_tr_list = prd_detail.find_all('tr')
print(prd_tr_list)태그 안의 텍스트 가져오기: get_text() 메서드
<td> 안의 텍스트를 가져오려면 Tag 객체의 get_text()메서드를 사용
for tr in prd_tr_list:
if tr.find('th').get_text() == '쪽수, 무게, 크기':
page_td = tr.find('td').get_text()
break
print(page_td)
# split()으로 쪽수만 가져오기
print(page_td.split()[0])전체 도서의 쪽수 구하기
앞의 과정을 하나의 함수(get_page_cnt())로 구현
- 온라인 서점의 검색 결과 페이지 URL 만들기
- requests.get()함수로 검색 결과 페이지의 HTML 가져오기
- 뷰티플수프로 HTML파싱
- 뷰티플수프의 find() 메서드로 < a > 태그를 찾아 상세 페이지 URL 추출
- requests.get()함수로 다시 도서 상세 페이지의 HTML 가져오기
- 뷰티플수프로 HTML 파싱
- 뷰티플수프의 find() 메서드로 '품목정보'< div > 태그 찾기
- 뷰티플수프의 find_all() 메서드로 '쪽수'가 들어있는 < tr > 태그 찾기
- 앞에서 찾은 테이블의 행에서 get_text() 메서드로 < td > 태그에 들어 있는 '쪽수'를 가져옴
def get_page_cnt(isbn):
# Yes24 도서 검색 페이지 URL
url = 'http://www.yes24.com/Product/Search?domain=BOOK&query={}'
# URL에 ISBN을 넣어 HTML 가져오기
r = requests.get(url.format(isbn))
soup = BeautifulSoup(r.text, 'html.parser') # HTML 파싱
# 검색 결과에서 해당 도서를 선택
prd_info = soup.find('a',attrs ={'class':'gd_name'})
# 도서 상세 페이지를 가져온다
url = 'http://www.yes24.com'+prd_info['href']
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
# 품목정보 <div>를 선택
prd_detail = soup.find('div',attrs = {'id':'infoset_specific'})
# 테이블에 있는 <tr>태그를 가져온다
prd_tr_list = prd_detail.find_all('tr')
# 쪽수가 들어 있는 <th>를 찾아 <td>에 담긴 값을 반환
for tr in prd_tr_list:
if tr.find('th').get_text() == '쪽수, 무게, 크기':
return tr.find('td').get_text().split()[0]
return ''
# 실행
get_page_cnt(9791190090018)데이터프레임 행 혹은 열에 함수 적용하기:apply() 메서드
# 10개의 행만 가져오기
top10_books = books.head(10)
# 새 데이터 프레임의 isbn13열만 get_page_cnt함수로 전달
def get_page_cnt2(row):
isbn = row['isbn13']
return get_page_cnt(isbn)
# apply 함수 사용
page_count = top10_books.apply(get_page_cnt2, axis = 1)
print(page_count)axis의 기본값을 0. 각 열에 대해 함수를 적용하라는 의미이다. 1은 행에 대해 함수를 적용한다.
데이터프레임과 시리즈 합치기:merge() 함수
page_count.name = 'page_count'
print(page_count)
top10_with_page_count = pd.merge(top10_books, page_count, left_index = True, right_index = True) # 두 객체의 인덱스 기준으로 합칠 경우: left_index = True, right_index = True
top10_with_page_count실습한 코랩
https://colab.research.google.com/drive/1cqXFwRqBASe1jgwYlrTzG5gMHqjVAfw6?usp=sharing
기본미션
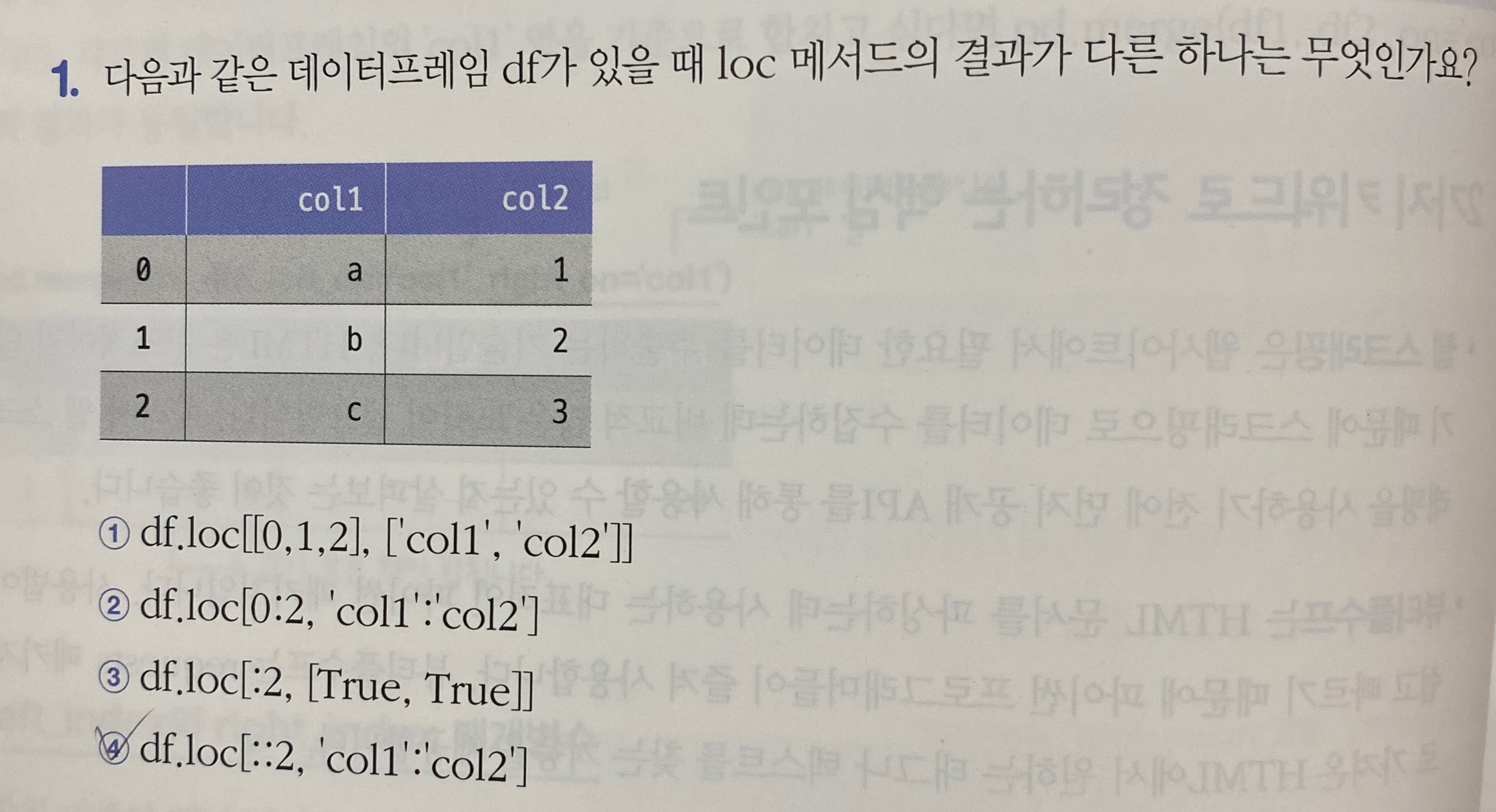
::2는 간격을 2씩 건너뛰게 되어 0,2,4...으로 보여야 된다.
선택미션

11번째 책의 쪽수를 가져왔다.
2주차 후기
API를 사용하는 것과 웹 크롤링을 사용해본 적은 다 R로 해봤었다. HTML을 정말 기초만 아는데 파이썬은 또 달라서 많이 어려웠다!
블로그를 처음 써봐서 실행결과도 공유할 수 있으면 좋겠다. 찾아봐야지..
'Data Analysis > 혼공학습단9기' 카테고리의 다른 글
| 혼자 공부하는 데이터 분석 with 파이썬: 4주차(Chapter 04-1) (0) | 2023.02.19 |
|---|---|
| 혼자 공부하는 데이터 분석 with 파이썬: 3주차(Chapter 03-2) (0) | 2023.01.26 |
| 혼자 공부하는 데이터 분석 with 파이썬: 3주차(Chapter 03-1) (0) | 2023.01.25 |
| 혼자 공부하는 데이터 분석 with 파이썬 : 2주차(Chapter 02-1) (0) | 2023.01.11 |
| 혼자 공부하는 데이터 분석 with 파이썬 : 1주차(Chapter 01) (0) | 2023.01.08 |


